Movie Recommendation Systems
This is a project I did for my masters research paper, where I build a recommendation system for a movies dataset.
The main reason behind carrying out this research was to understand how big tech companies recommend items to its users, companies like Amazon, Netflix, Spotify and many more use recommendation systems to recommend items to its users on a daily basis.
Overview
Recommendation system work on the principal of “homophily” which means similar users prefer similar items, this means that companies are able to accurately predict which users is most likely to buy something / watch something.
There are 2 main types of data that is gathered when building recommendation systems, these are :
-
Explicit Data - Data which is easily available, these include number of stars given to a movie, or number of rating given to a product.
-
Implicit Data - This is the type of data which is not easily accessible, these type of data include the number of minutes a user stays on a platform etc. This type of data includes everything excluding the ratings data.
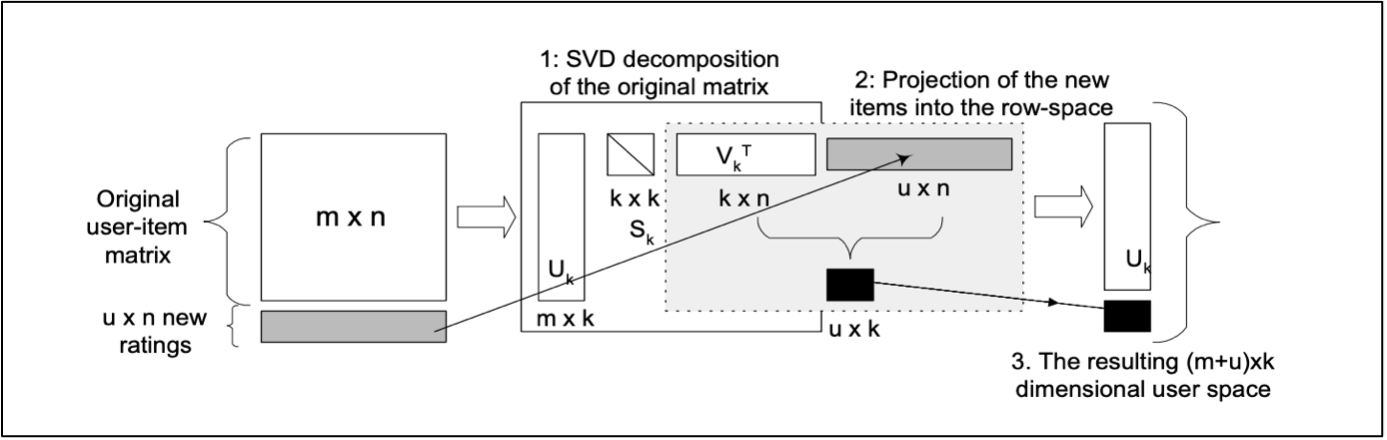
The following research paper uses the Movielens dataset to build a recommendation system, using both content based and collaborative filtering techniques. A range of algorithms are used to build the recommendation system, these include: K-Nearest Neighbours, TF-IDF, Singular Value Decomposition Model (SVD), Alternating least Square (ALS) and various hyper-parameter tuning is carried out to optimise the SVD and ALS models.
The following research paper is currently published on SSRN
Moreover, The code for the recommendation model can be found on my GitHub Repository
Overview Of The Singular Value Decomposition Architecture